 587
587
 0
0
 2025-02-26
2025-02-26
 2025-02-26
2025-02-26
【例會(huì)預(yù)告】
會(huì)議名稱(chēng):數(shù)據(jù)科學(xué)與創(chuàng)新管理團(tuán)隊(duì)例會(huì)
會(huì)議時(shí)間:2025年02月27日(周四)14:30-17:00
會(huì)議地點(diǎn):經(jīng)管樓607會(huì)議室
匯報(bào)人: 李虎峰
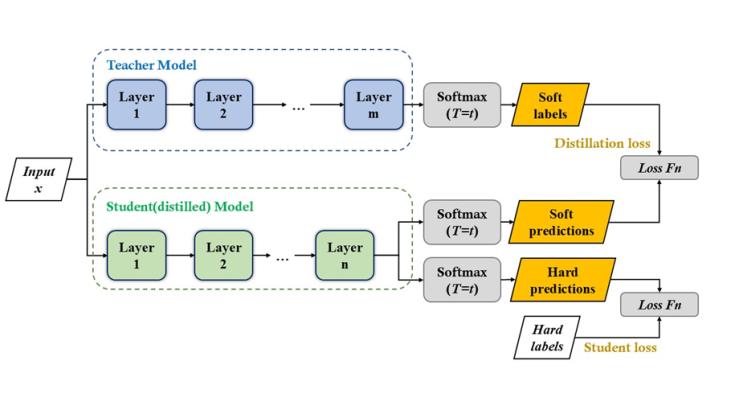
匯報(bào)題目:Distilling the Knowledge in a Neural Network(深度神經(jīng)網(wǎng)絡(luò)中的知識(shí)蒸餾)
匯報(bào)摘要:
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome and may be too computationally expensive to allow deployment to a large number of users, especially if the individual models are large neural nets. Caruana and his collaborators have shown that it is possible to compress the knowledge in an ensemble into a single model which is much easier to deploy and we develop this approach further using a different compression technique. We achieve some surprising results on MNIST and we show that we can significantly improve the acoustic model of a heavily used commercial system by distilling the knowledge in an ensemble of models into a single model. We also introduce a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full models confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel.
載")
贊")







載")