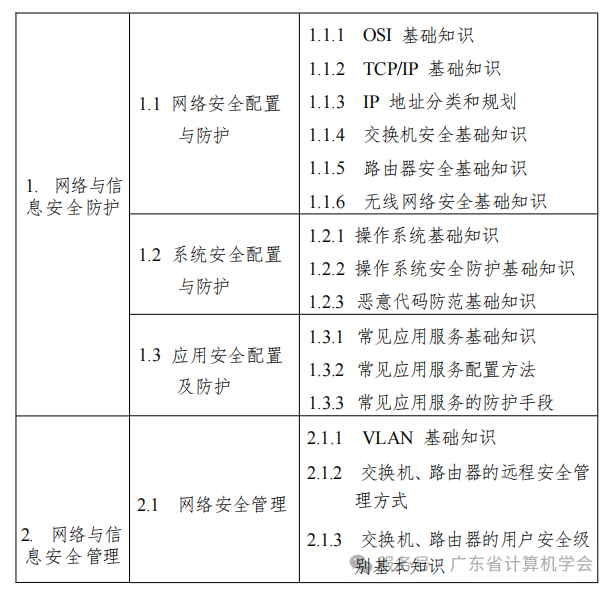
第四屆環(huán)境工程與可持續(xù)能源國際會(huì)議(EESE 2025)由湖南農(nóng)業(yè)大學(xué)主辦��,中南林業(yè)科技大學(xué)協(xié)辦�,將于2025年11月21日至23日在中國·長沙召開。
EESE 2025旨在聚集領(lǐng)先的科學(xué)家��、研究人員和學(xué)者��,共同交流和分享在環(huán)境工程與可持續(xù)能源相關(guān)各個(gè)方面的經(jīng)驗(yàn)和研究成果���,為研究人員�����、從業(yè)者和教育工作者提供一個(gè)重要的跨學(xué)科平臺(tái)�����,以展示該領(lǐng)域產(chǎn)�、學(xué)、研的最新趨勢(shì)�、面臨的挑戰(zhàn)及可行解決方案。我們誠摯地歡迎國內(nèi)外學(xué)者拔冗蒞臨���,展示最新的研究和成果�����,分享不同的觀點(diǎn)和經(jīng)驗(yàn)���,為環(huán)境工程與可持續(xù)能源的發(fā)展夯實(shí)理論基礎(chǔ)、拓展可能性科研樣本����。
會(huì)議信息
會(huì)議簡(jiǎn)稱:EESE 2025
會(huì)議全稱:2025年環(huán)境工程與可持續(xù)能源國際會(huì)議(The 4rd International Conference on Environmental Engineering and Sustainable Energy)
主辦單位:湖南農(nóng)業(yè)大學(xué)
協(xié)辦單位:中南林業(yè)科技大學(xué)
會(huì)議官網(wǎng):www.iceese.net
官方郵箱:EESEzwh@126.com
會(huì)議日期:2025年11月21日至23日
二輪截稿:11月20日
主講嘉賓
張華 中國科學(xué)院地球化學(xué)研究所
國家杰青
中國科學(xué)院大學(xué)博士生導(dǎo)師�����,中國科學(xué)院地球化學(xué)研究所二級(jí)研究員�����,環(huán)境地球化學(xué)國家重點(diǎn)實(shí)驗(yàn)室副主任����。貴州省土壤重金屬污染控制與生態(tài)修復(fù)工程研究中心主任����。他連續(xù)入選斯坦福大學(xué)和愛思唯爾世界前2%的科學(xué)家(2022-2024)��,并被公認(rèn)為Clarivate Analytics全球前1%高被引研究員(2024)��。他的研究主要集中在“快速環(huán)境健康診斷和綠色修復(fù)”的跨學(xué)科領(lǐng)域���,包括:[1]“硒-重金屬相互作用和風(fēng)險(xiǎn)評(píng)估”����;[2]“綠色可持續(xù)整治與環(huán)境健康”��;[3]“智能傳感器和環(huán)境分子診斷”����。在過去的十年中,他主持了30多項(xiàng)研究項(xiàng)目�����,其中包括國家重點(diǎn)研發(fā)計(jì)劃、國家自然科學(xué)基金(重點(diǎn)項(xiàng)目和聯(lián)合基金)�����、中國科學(xué)院STS/重點(diǎn)部署項(xiàng)目����。發(fā)表學(xué)術(shù)論文100余篇,撰寫英文專著1部(施普林格)�,與人合著中文專著6部。他的研究成果被《科學(xué)新聞》�、BBC、《科學(xué)日?qǐng)?bào)》���、《獨(dú)立報(bào)》等60多家國際知名科學(xué)媒體廣泛報(bào)道�����。
孫紅文 南開大學(xué)
國家杰青
孫紅文博士����,教授���,中國南開大學(xué)環(huán)境科學(xué)與工程學(xué)院前院長。1994年獲南開大學(xué)博士學(xué)位���,至今在南開大學(xué)工作��。1999-2001年在日本大阪大學(xué)做博士后����,2008年在瑞士聯(lián)邦水技術(shù)研究所做訪問學(xué)者。主持:1)教育部新興污染物環(huán)境過程與風(fēng)險(xiǎn)評(píng)估中心學(xué)科創(chuàng)新與國際交流中心�����;2)中國科學(xué)與工程部風(fēng)險(xiǎn)評(píng)估與污染修復(fù)創(chuàng)新團(tuán)隊(duì)���;主要研究方向?yàn)椋?)全氟烷基�、增塑劑�����、阻燃劑等新興有機(jī)污染物的來源�����、命運(yùn)和人體暴露�����;2)污染土壤修復(fù)的新材料和新技術(shù)。她發(fā)表了600多篇期刊論文和幾個(gè)書籍章節(jié)�,并編輯了一本專著“生物炭與環(huán)境”。論文被引用超過1.5萬次��,被Elsevier評(píng)為高被引學(xué)者�。她被教育部、科技部和中國自然科學(xué)基金委員會(huì)授予多項(xiàng)人才稱號(hào)����。她目前是《環(huán)境科學(xué)與技術(shù)》雜志的顧問委員會(huì)成員,并擔(dān)任其他幾家國內(nèi)和國際期刊的編輯委員會(huì)成員?�,F(xiàn)任中國土壤學(xué)會(huì)常務(wù)理事�、新興污染物污染控制專業(yè)委員會(huì)副主任委員,并擔(dān)任多個(gè)學(xué)術(shù)委員會(huì)委員�。
馬靜 上海電力大學(xué)
IET Fellow
教授,博士生導(dǎo)師�,愛思唯爾高被引研究員(全球),全球最具影響力科學(xué)家前2%(斯坦福大學(xué))����,IET Fellow, IEEE資深會(huì)員�����。記者分別于2003年和2008年獲得華北電力大學(xué)電力系統(tǒng)與自動(dòng)化專業(yè)學(xué)士學(xué)位和博士學(xué)位��。2008年9月至2009年9月��,在美國弗吉尼亞理工大學(xué)從事博士后研究工作��。記者兼任第六屆全國技術(shù)預(yù)測(cè)能源領(lǐng)域?qū)<医M組長���、CIGRE中國全國委員會(huì)青年分會(huì)理事長���、中國電工學(xué)會(huì)青年工作委員會(huì)副主任委員、《IET可再生能源發(fā)電》��、《電力系統(tǒng)保護(hù)與控制》等期刊編委���。長期從事新能源和交直流電網(wǎng)環(huán)境下的系統(tǒng)安全防護(hù)研究���。主持國家級(jí)項(xiàng)目6項(xiàng),在國內(nèi)外權(quán)威學(xué)術(shù)期刊發(fā)表學(xué)術(shù)論文100余篇���,授權(quán)國際/國家發(fā)明專利90余項(xiàng)�����;出版中英文專著5部�;獲省部級(jí)一等獎(jiǎng)5項(xiàng)。
梁耀彰 香港大學(xué)
IMechE Fellow
梁教授于一九八二年獲香港大學(xué)機(jī)械工程系學(xué)士學(xué)位及一九八八年獲博士學(xué)位���。梁教授于1993年加入港大機(jī)械工程系擔(dān)任講師���,2007年成為正教授,并于2020年擔(dān)任系主任至2023年����。梁教授主要從事環(huán)境污染控制、可再生能源及清潔能源的研究�����。在《自然通訊》�、《能源與環(huán)境科學(xué)》、《先進(jìn)材料》等SCI頂級(jí)期刊發(fā)表論文600余篇�,其中同行評(píng)議論文370余篇。他目前的h指數(shù)是101�����,總引用數(shù)是53000+。自2010年以來��,他是世界能源領(lǐng)域高被引科學(xué)家前1% (Essential Science Indicators)之一����,并于2017年至2022年連續(xù)六年被Clarivate Analytics評(píng)為高被引研究員��。梁教授在多個(gè)國際會(huì)議上發(fā)表了90多次主題演講和特邀演講�。梁教授是特許工程師、IMechE及能源研究所院士�。他亦曾任能源學(xué)會(huì)(香港分會(huì))前任主席,現(xiàn)為《應(yīng)用能源》���、《能源轉(zhuǎn)換與管理》�、《應(yīng)用科學(xué)》��、《能源進(jìn)展》及《可再生能源與可持續(xù)能源》等多份期刊的編委�。梁教授亦擔(dān)任香港工程師學(xué)會(huì)及能源學(xué)會(huì)(香港)等多個(gè)學(xué)會(huì)的顧問、香港特別行政區(qū)政府多個(gè)委員會(huì)主席及委員�����,以及與可持續(xù)能源及環(huán)境有關(guān)的政府上訴委員會(huì)���。梁教授于2008年獲得香港環(huán)保先鋒獎(jiǎng)����,并于2024年獲得國際先進(jìn)材料協(xié)會(huì)頒發(fā)的先進(jìn)材料獎(jiǎng)。
周耀渝 湖南農(nóng)業(yè)大學(xué)
環(huán)境與生態(tài)學(xué)院院長
湖南農(nóng)業(yè)大學(xué)教授�、博士生導(dǎo)師,環(huán)境與生態(tài)學(xué)院院長��,生態(tài)學(xué)一級(jí)學(xué)科博士點(diǎn)領(lǐng)銜人����。“十四五”國家重點(diǎn)研發(fā)計(jì)劃—青年科學(xué)家項(xiàng)目負(fù)責(zé)人,湖南省科技創(chuàng)新領(lǐng)軍人才�����。湖南大學(xué)博士�����,Hong Kong Polytechnic University博士后/研究員�����,清華大學(xué)訪問學(xué)者/研究員���,長期從事納米農(nóng)業(yè)與農(nóng)業(yè)生態(tài)環(huán)境保護(hù)領(lǐng)域研究工作�。
組委會(huì)成員
General Chairs
Farhad SHAHNIA Murdoch University
楊春明 湖南師范大學(xué)
Program Chairs
周耀渝 湖南農(nóng)業(yè)大學(xué)
Raul Muñoz, Universidad de Valladolid
胡新將 中南林業(yè)科技大學(xué)
Technical Chairs
雷鳴 湖南農(nóng)業(yè)大學(xué)
Marwa Elkady 埃及日本科技大學(xué)
Publication Chair
譚小飛 湖南大學(xué)
Technical Program Committees
劉剛 中南大學(xué)
丁濤, 西安交通大學(xué)
張樂華, 華東理工大學(xué)
解玉磊, 廣東工業(yè)大學(xué)
吳少鵬, 武漢理工大學(xué)
劉運(yùn)德,中國地質(zhì)大學(xué)
周航,中南林業(yè)科技大學(xué)
陳安偉��,湖南農(nóng)業(yè)大學(xué)
徐熙焱���,北京理工大學(xué)
黃柱堅(jiān)��,華南農(nóng)業(yè)大學(xué)
李美芳,中南林業(yè)科技大學(xué)
Elisa Marrasso,University of Sannio,Italy
Maria G. Ioannides,National Technical University of Athens,Greece
Maciej Dzikuc,University of Zielona Gora,Poland
Hossam Elaqra,University of Palestine,Palestine
Roya Dastjerdi,Yazd University,Yazd,Iran
Betul GURUNLU,Uskudar University,Türkiye
Guene Lougou Bachirou, Harbin Institute of Technology,China
Temitope Adefarati, University of Pretoria,South Africa
Sintayehu Alemnew,Adama Science and Technology University, Ethiopia
Nurdan BUYUKKAMACI, Dokuz Eylul University, Turkey
Murat Erdem,Firat University,Turkey
Nimay Chandra Giri, Centurion University of Technology and Management (CUTM), India
......(詳情可見官網(wǎng))
征稿主題
環(huán)境工程:
•大氣科學(xué)與空氣污染控制
•收集系統(tǒng)的優(yōu)化
•回收和再利用
•碳中和
•環(huán)境可持續(xù)性
•臭氧層損耗
•處理和處置方法的技術(shù)方面(填埋����,熱處理等)
•碳捕集與封存
•空氣污染與控制
•核能工程
•固體廢物管理
•熱力工程
•減少廢物
•熱力和電力系統(tǒng)
•地球科學(xué)
•環(huán)境生物技術(shù)
•環(huán)境與資源科學(xué)與技術(shù)
•環(huán)境修復(fù)技術(shù)
•大氣環(huán)境
•生態(tài)環(huán)境
•廢水處理與水污染控制
•水生態(tài)修復(fù)與流域治理
可持續(xù)能源:
•清潔能源和可再生能源開發(fā)利用
•廢物回收能源
•氫能
•風(fēng)能
•生物質(zhì)能
•能源存儲(chǔ)和燃料電池
•地?zé)崮?
•綜合能源系統(tǒng)
•海洋科學(xué)
•能量轉(zhuǎn)換
•海洋能源
•新能源汽車動(dòng)力系統(tǒng)及控制系統(tǒng)
•太陽能
•節(jié)能和能源回收
•太陽能發(fā)電和光伏應(yīng)用
•可再生加熱和冷卻,包括高溫應(yīng)用
•未來能源系統(tǒng)的數(shù)字化
•生物燃料
投稿指南&注冊(cè)費(fèi)用
1. 論文模板:http://www.iceese.net/submission/
2.投稿系統(tǒng):
https://ocs.academicenter.com/main?short_name=EESE
3.請(qǐng)根據(jù)以下幾點(diǎn)準(zhǔn)備您的論文:
(1)全英文稿件����,非純綜述類,應(yīng)具有學(xué)術(shù)或?qū)嵱猛茝V價(jià)值�,并且未在國內(nèi)外學(xué)術(shù)期刊或會(huì)議發(fā)表過。
(2)摘要���、關(guān)鍵詞和結(jié)論部分需體現(xiàn)會(huì)議主題�,文章主要收錄技術(shù)型的文章�����,需要有方法、圖表��、實(shí)驗(yàn)數(shù)據(jù)和結(jié)果��。
(3)作者可通過iThenticate����、CrossRef查重,重復(fù)率包含文獻(xiàn)不得超過25%����。
(4)文章頁面需要控制在8頁(包含第8頁),含公式圖表等����,超過8頁需繳納超頁費(fèi)。
4.投稿后7-15個(gè)工作日內(nèi)反饋審稿意見或錄用通知���。
5. 若您的文章被錄用����,我們將以郵件形式通知您,您將收到以下文件:錄用通知����、審稿意見表、注冊(cè)須知�����、會(huì)議注冊(cè)表��、終稿確認(rèn)函���。
6.請(qǐng)?jiān)谑盏戒浻猛ㄖ?個(gè)工作日內(nèi)完成注冊(cè)���,并將文章終稿�、注冊(cè)表、查重報(bào)告�、匯款憑證、學(xué)生證照片(學(xué)生注冊(cè))��、終稿確認(rèn)函上傳至投稿系統(tǒng)�。如有特殊情況需要延期注冊(cè),請(qǐng)及時(shí)告知組委會(huì)����。
7.注冊(cè)費(fèi)用
會(huì)議注冊(cè)類型
注冊(cè)費(fèi)用
A.學(xué)生注冊(cè)
3400元 /篇
B.一般作者注冊(cè)
3600元 /篇
C.超頁費(fèi)(超過8頁)
300元 /頁
D.參會(huì)/報(bào)告
1500元 /人
參與形式
1. Committee
作為大會(huì)主席�����、指導(dǎo)主席或技術(shù)主席�、TPC等身份參會(huì)支持�����,在會(huì)議技術(shù)層面上指導(dǎo)把關(guān)����,負(fù)責(zé)一部分同行評(píng)審環(huán)節(jié),組委會(huì)將頒發(fā)榮譽(yù)證書�����。Committee申請(qǐng)需提供個(gè)人學(xué)術(shù)簡(jiǎn)歷���。
2. Reviewer
作為會(huì)議的審稿專家參與支持�,負(fù)責(zé)在專業(yè)領(lǐng)域內(nèi)對(duì)稿件進(jìn)行同行評(píng)審�,組委會(huì)將頒發(fā)審稿專家證書。Reviewer申請(qǐng)需提供個(gè)人學(xué)術(shù)簡(jiǎn)歷����。
3. Presenter
(1) 分論壇:針對(duì)會(huì)議主題組建workshop��,并邀請(qǐng)相同研究領(lǐng)域的專家����、學(xué)者加入����,以分論壇形式展開研討。
注:研討會(huì)形式可同時(shí)進(jìn)行論文投稿��、口頭報(bào)告����、聽眾參加,時(shí)長和具體流程可酌情而定����。workshop Chair申請(qǐng)需要提供個(gè)人學(xué)術(shù)簡(jiǎn)歷��。
(2) 口頭報(bào)告:在大會(huì)上就報(bào)告人目前的研究等進(jìn)行口頭英文學(xué)術(shù)報(bào)告(不需要投稿)���,時(shí)長約10-15分鐘��。
(3) 書面論文報(bào)告:在大會(huì)征稿主題范圍內(nèi)提交相關(guān)領(lǐng)域英文科技論文��,評(píng)審?fù)ㄟ^后提交注冊(cè)并收錄到會(huì)議論文集�。
(4) 海報(bào)展示:投稿論文除進(jìn)行現(xiàn)場(chǎng)或線上口頭報(bào)告外,還可選擇現(xiàn)場(chǎng)海報(bào)展示�,將文章關(guān)鍵成果及摘要展示給現(xiàn)場(chǎng)參會(huì)嘉賓。
4. Audience
作為聽眾參加線下會(huì)議的報(bào)告分享及活動(dòng)交流�。
會(huì)議日程安排
2025年11月21日
09:00-20:00
現(xiàn)場(chǎng)報(bào)到
2025年11月22日
08:30—12:00
開幕式&主題報(bào)告
12:00—14:00
午餐&休息
14:00—18:00
特邀報(bào)告&分會(huì)場(chǎng)報(bào)告
18:00—20:00
晚宴&頒獎(jiǎng)儀式
2025年11月23日
全天
學(xué)術(shù)考察(待定)
聯(lián)系方式
組委會(huì)郵箱:EESEzwh@126.com
組委會(huì)編輯皮老師Tel/WeChat:+86 18684805810